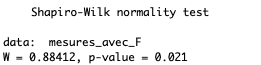Introduction et analyse de données avec– le langage de programmation destiné aux statistiques 📊 et à la science des données 🔍
R est un environnement logiciel puissant dédié au calcul statistique, largement utilisé en science des données pour la visualisation et l'analyse approfondie des données.
Il se distingue par ses nombreuses bibliothèques spécialisées, permettant de réaliser des analyses statistiques avancées, tout en offrant des outils de visualisation performants et personnalisables.
Bien qu’il soit un véritable langage de programmation, R est principalement exploité pour ses fonctionnalités statistiques et non pour le développement d'applications logicielles complètes. Il est donc utile de garder à l’esprit que R vous sera avant tout utile pour écrire des scripts et automatiser des analyses de données complexes, telles que les régressions, les analyses de variance et les tests d'hypothèses.
Utilisation de la console de R et assignation de variables
Il existe deux façons de travailler avec R : soit directement dans la console (qui est un interprète), soit dans une fenêtre de script (ouvrir un nouveau document).
Chargement de la vidéo...
Assignation de variables
Pour lister les éléments de la session R stockés dans la mémoire de votre ordinateur, il faut appeler la fonction ls()
Ici, nommons la base de données data.csv
Format : texte (csv)
Il y a 21 enregistrements et 2 champs :
mesures_sans_F et mesures_avec_F
Récupérer le contenu d’un fichier texte :
Lorsque l'on travaille avec des fichiers de données au format CSV (Comma-Separated Values) dans R, voici comment charger les données dans R :
data <- read.table(file = "~/Downloads/data.csv", sep = ";", dec = ",", header = TRUE)
• Le fichier data.csv est dans cet exemple situé dans le dossier Downloads. Vous pouvez glisser directement votre fichier dans la console R et ainsi obtenir le chemin de votre fichier automatiquement et remplacer « ~/Downloads/data.csv »
• Les colonnes du fichier sont séparées par des points-virgules (;).
• Les nombres décimaux utilisent une virgule (",") comme séparateur.
• La première ligne du fichier est interprétée comme l'entête avec les noms des colonnes.
Quelques conseils :
• Toujours vérifier le séparateur : si vous avez un doute sur le séparateur de champ ou de décimale utilisé dans un fichier, ouvrez-le dans un éditeur de texte pour le vérifier manuellement.
• Si votre fichier utilise une virgule comme séparateur de champ et un point comme séparateur décimal (notation anglo-saxonne), vous pouvez utiliser directement la fonction read.csv(), qui est une version simplifiée de read.table().
attach(data) rend les colonnes de data (les variables du jeu de données) utilisables directement par leur nom, sans avoir à spécifier data$mesures_sans_F, par exemple.
Ainsi, dans notre exemple, après avoir utilisé la commande attach(), on peut accéder directement aux colonnes mesures_sans_F ou mesures_avec_F
names(data) permet d'afficher les noms des colonnes du jeu de données data.
Le résultat montre que le fichier contient deux colonnes :
• mesures_sans_F
• mesures_avec_F
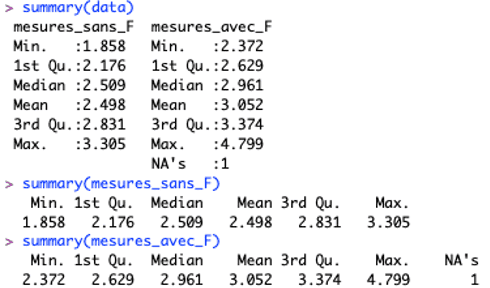
Obtenir un résumé de la distribution de variables quantitatives continues
La fonction summary() dans R permet d’obtenir des statistiques descriptives.
Utilisation de summary() avec data et nos colonnes
La commande summary(data) produit ici un résumé statistique pour toutes les colonnes du jeu de données data. Deux colonnes sont résumées : mesures_sans_F et mesures_avec_F.
Le résumé inclut :
• Min. (Minimum) : la plus petite valeur de la série.
• 1st Qu. (Premier quartile) : la valeur en dessous de laquelle se trouve 25 % des données.
• Median (Médiane) : la valeur qui divise la série en deux parties égales. 50 % des données sont inférieures à cette valeur.
• Mean (Moyenne) : la moyenne arithmétique des valeurs.
• 3rd Qu. (Troisième quartile) : la valeur en dessous de laquelle se trouvent 75 % des données.
• Max. (Maximum) : la plus grande valeur de la série.
• NA's : le nombre de valeurs manquantes. Dans mesures_avec_F, il y a une valeur manquante (NA).
Graphiques de base
Chargement de la vidéo...
Réaliser le graphe de la boîte à moustache d’une distribution : la fonction boxplot()
Pour résumer une variable de manière simple et visuelle, vous pouvez utiliser la fonction boxplot(). Ce graphique affiche la médiane, avec les quartiles représentés aux bords du rectangle, tandis que les valeurs maximales et minimales se situent aux extrémités des « moustaches ». Ainsi, le boxplot offre une représentation claire de la distribution des données et des éventuelles valeurs aberrantes.
Pour créer un boxplot, voici un exemple simple : boxplot(mesures_avec_F)
boxplot(mesures_avec_F)
boxplot(mesures_sans_F)
Configurer la disposition des graphiques dans une seule fenêtre graphique
Pour diviser l'espace de la fenêtre graphique en plusieurs sous-espaces afin d'afficher plusieurs graphiques côte à côte on utilise la fonction par() avec l'argument mfrow ou mfcol. La différence réside simplement dans l'ordre de remplissage
mfrow = c(nr, nc) : divise la fenêtre en une matrice de nr lignes et nc colonnes, et les graphiques sont remplis ligne par ligne. mfcol = c(nr, nc) : divise la fenêtre en une matrice de nr lignes et nc colonnes, mais cette fois, les graphiques sont remplis colonne par colonne.
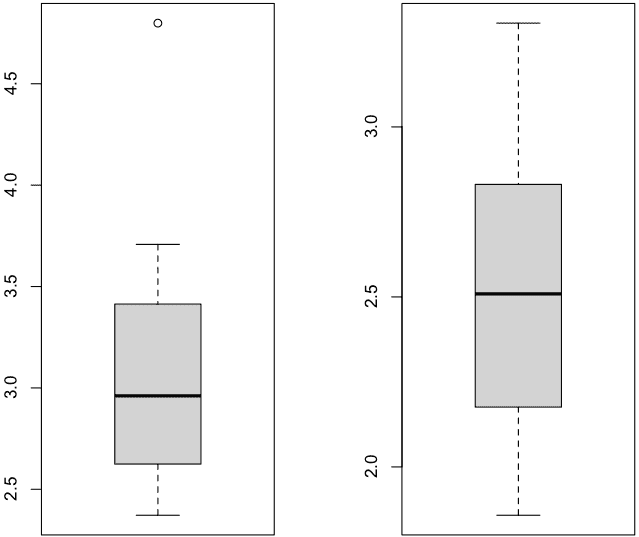
par(mfrow=c(1,2)) # Afficher 1 ligne et 2 colonnes de graphiques
# sert à ajouter un commentaire afin d’ajouter des explications.
Utilisation de la fonction par() puis choix des boxplot dans la console
Cette fenêtre s'affiche après avoir tapé les commandes ci-dessus (à gauche ici : en présence de F / à droite : en absence de F)
Vous pouvez ainsi comparer facilement vos distributions en quatre parties d’égales fréquences de 25 % chacune.
• Min : la plus petite donnée de la série
• Q1 : le point où 25 % des données sont en dessous (premier quartile). Il correspond à la limite inférieure du rectangle (ou boîte).
• Me : la médiane (trait noir)
• Q3 : le point où 75 % des données sont en dessous (troisième quartile). Il correspond à la limite supérieure du rectangle.
• Max : la plus grande donnée
Un rectangle (ou boîte) englobe les valeurs entre Q1 et Q3 pour représenter l'écart interquartile, qui est la mesure de la dispersion des 50 % centraux des données.
Les moustaches s'étendent à partir des bords de la boîte jusqu’à la plus petite et la plus grande valeur qui ne sont pas valeurs aberrantes.
Réinitialiser la disposition
Si vous souhaitez revenir à une seule fenêtre graphique après avoir affiché vos boxplot, utilisez la commande suivante :
par(mfrow=c(1,1)) # Réinitialiser à 1 graphique par ligne
Lorsque vous afficherez vos prochains boxplot, cela reviendra à un seul graphique.
Création et édition d’un fichier scénario (script de commandes)
Récapitulons ce que nous avons vu jusqu'ici :
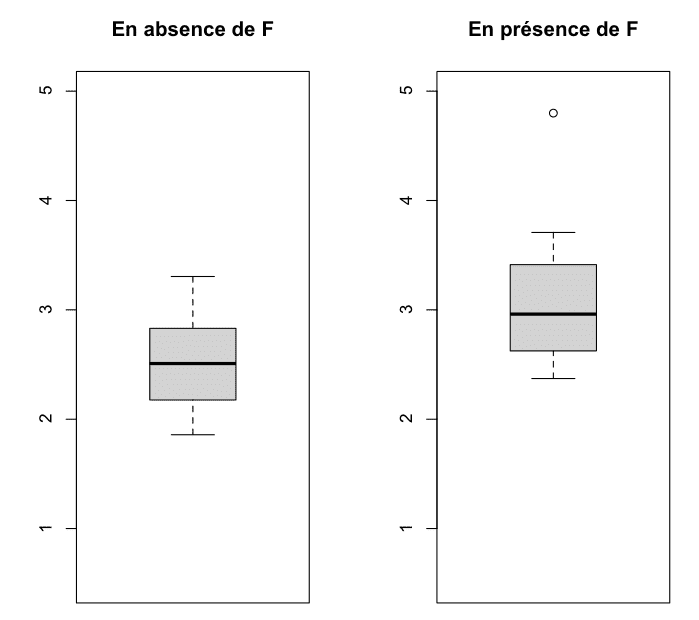
############################# # Analyse de données – Script # ############################## Nettoyage de l'environnementrm(list = ls(all = TRUE)) # Efface toutes les variables# Chargement des donnéesdata <- read.table(file ="~/Downloads/data.csv", sep = ";", dec = ",", header = TRUE)attach(data) # Accès direct aux colonnes# Statistiques descriptivessummary(mesures_sans_F)summary(mesures_avec_F)# Configuration graphiquepar(mfrow = c(1, 2))# Affichage des boxplotsboxplot(mesures_sans_F, main = "En absence de F", ylim = c(0.5, 5))boxplot(mesures_avec_F, main = "En présence de F", ylim = c(0.5, 5))# Détacher les données (optionnel)detach(data)
Le fait de spécifier les mêmes limites ylim pour les deux graphiques garantit que la comparaison visuelle entre les deux séries de données sera plus précise, car les deux boxplot seront tracés sur la même échelle.
main="En absence de F" est un argument qui personnalise le titre du boxplot. Ici, le titre "En absence de F" sera affiché en haut du graphique
Afin que vous puissiez concevoir ce script :
Sur Windows : Fichier → Nouveau script Sur macOS : Fichier → Nouveau document
Une fois le fichier réalisé, vous pouvez sauvegarder ce fichier avec un nom explicite dans un répertoire que vous aurez préparé à cet effet.
Vous pourrez l’exécuter qu’une fois qu’il sera enregistré.
Pour lancer le script :
source('~/Downloads/data.R', chdir = TRUE) # lien vers votre fichier R
Cette fenêtre s'affiche après avoir exécuté le script
Ajoutons quelques paramètres aux boxplots pour améliorer leur esthétique et faciliter la distinction entre les différentes séries de données. De plus, intégrons des titres de sections clairs dans le code de chaque étape du script, afin de permettre une navigation rapide et intuitive à travers les différentes parties.
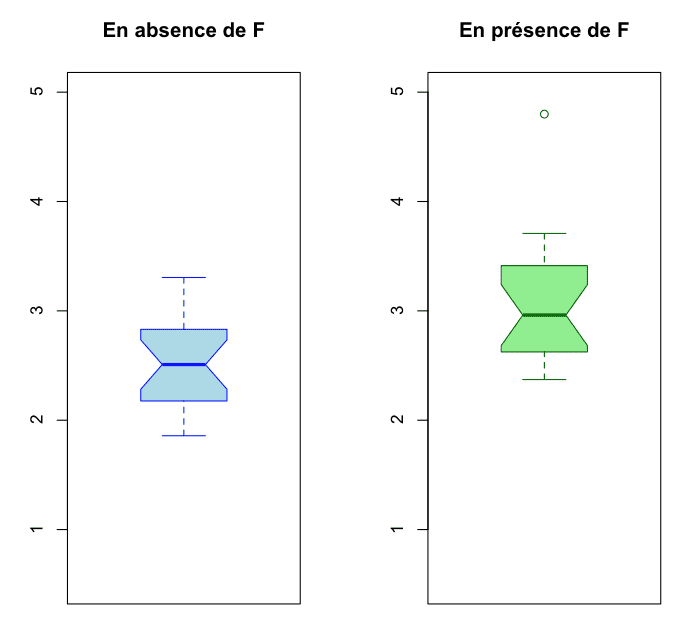
############################ Analyse de données – Script ############################# Nettoyage de l'environnement# ----------------------------rm(list = ls(all = TRUE)) # Efface toutes les variables de la session en cours# Chargement des données# ----------------------# Récupération des données depuis le fichier CSVdata <- read.table(file = "~/Downloads/data.csv", sep = ";", dec = ",", header = TRUE)attach(data) # Rend les colonnes accessibles directement par leur nomnames(data) # Affiche les noms des colonnes du fichier data# Statistiques descriptives# -------------------------# Résumés des donnéessummary(mesures_sans_F) # Résumé pour les mesures sans Fsummary(mesures_avec_F) # Résumé pour les mesures avec F# Configuration de la fenêtre graphique# -------------------------------------par(mfrow = c(1, 2)) # Divise l'espace graphique en 1 ligne et 2 colonnes# Affichage des boîtes à moustaches (boxplots)# --------------------------------------------boxplot(mesures_sans_F,
main = "En absence de F", # Titre du graphique
ylim = c(0.5, 5), # Limites de l'axe Y
col = "lightblue", # Couleur de la boîte
border = "blue", # Couleur des bordures
notch = TRUE) # Ajout d'une encoche à la boîteboxplot(mesures_avec_F,
main = "En présence de F", # Titre du graphique
ylim = c(0.5, 5), # Limites de l'axe Y
col = "lightgreen", # Couleur de la boîte
border = "darkgreen", # Couleur des bordures
notch = TRUE) # Ajout d'une encoche à la boîte# Détacher les données# ---------------------detach(data) # Nettoyage : détacher l'objet 'data' de la session
Le paramètre col dans un boxplot() définit la couleur de remplissage de la boîte.
border permet de définir la couleur des bordures.
L'ajout d'une encoche (option notch = TRUE dans la fonction boxplot) permet de visualiser la médiane de façon plus distincte dans un graphique à boîte à moustaches.
Relançons à nouveau le script :
source('~/Downloads/data.R', chdir = TRUE) # lien vers votre fichier R
Cette nouvelle fenêtre s'affiche après avoir exécuté le script
Test d’hypothèse pour comparer 2 distributions
Test sur la normalité des distributions de données avec le test de Shapiro-Wilk
Le test de Shapiro-Wilk permet de vérifier si la série de données suit une loi normale.
La statistique de test (W) :
Une valeur W plus élevée indique que vos données suivent de près une distribution normale. Il varie de 0 à 1, les valeurs plus proches de 1 suggérant une normalité.
La valeur P (p_value) :
La valeur p nous indique s'il faut rejeter l'hypothèse nulle (que les données sont normalement distribuées).
Analyser la valeur :
Un seuil commun est de 0,05 (5%) :
• Si la valeur p est supérieure à 0,05, nous ne parvenons pas à rejeter l’hypothèse nulle, ce qui suggère que les données sont normalement distribuées, cela signifie qu'elles suivent une distribution normale. Cette distribution est caractérisée par une symétrie parfaite autour de la moyenne, avec une majorité des valeurs regroupées autour de la moyenne et des occurrences plus rares pour les valeurs extrêmes.
• Si la valeur p est inférieure ou égale à 0,05, nous rejetons l'hypothèse nulle, indiquant que les données ne suivent pas une distribution normale.
Pour limiter le risque on peut aussi souhaiter que cette valeur P soit supérieure à 0,2 (donc 20%).
shapiro.test(vecteur1) shapiro.test(vecteur2)
Dans notre exemple : shapiro.test(mesures_sans_F)
Le test de Shapiro-Wilk
P_value est inférieur à 5% (ainsi qu’à notre seuil de sécurité de 20%), nous ne pouvons donc pas retenir l’hypothèse que notre distribution suit la loi normale (également appelée distribution gaussienne).
Si c’était le cas, nous aurions pu faire un test paramétrique (test de Student ou test t).
Découvrez notre site web principal pour approfondir vos connaissances avec nos cours de lycée et profiter de notre outil de mémorisation espacée, conçu pour être utile à tous les âges.








 – le langage de programmation destiné aux statistiques 📊 et à la science des données 🔍
– le langage de programmation destiné aux statistiques 📊 et à la science des données 🔍



.png)
.png)